This content refers to the previous stable release of PyMVPA.
Please visit
www.pymvpa.org for the most
recent version of PyMVPA and its documentation.
measures.base
Module: measures.base
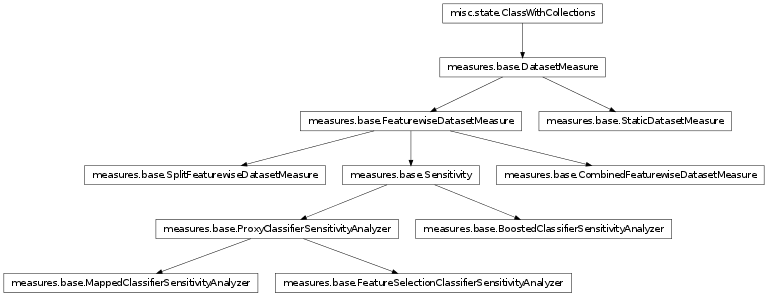
Inheritance diagram for mvpa.measures.base:
Base class for data measures: algorithms that quantify properties of
datasets.
Besides the DatasetMeasure base class this module also provides the
(abstract) FeaturewiseDatasetMeasure class. The difference between a general
measure and the output of the FeaturewiseDatasetMeasure is that the latter
returns a 1d map (one value per feature in the dataset). In contrast there are
no restrictions on the returned value of DatasetMeasure except for that it
has to be in some iterable container.
Classes
-
class mvpa.measures.base.BoostedClassifierSensitivityAnalyzer(*args_, **kwargs_)
Bases: mvpa.measures.base.Sensitivity
Set sensitivity analyzers to be merged into a single output
Note
Available state variables:
- base_sensitivities: Stores basic sensitivities if the sensitivity relies on combining multiple ones
- null_prob+: State variable
- null_t: State variable
- raw_results: Computed results before applying any transformation algorithm
(States enabled by default are listed with +)
See also
Please refer to the documentation of the base class for more information:
Sensitivity
Initialize instance of BoostedClassifierSensitivityAnalyzer
| Parameters: |
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
|
|---|
-
combined_analyzer
-
untrain()
Untrain BoostedClassifierSensitivityAnalyzer
-
class mvpa.measures.base.CombinedFeaturewiseDatasetMeasure(analyzers=None, combiner=None, **kwargs)
Bases: mvpa.measures.base.FeaturewiseDatasetMeasure
Set sensitivity analyzers to be merged into a single output
Note
Available state variables:
- base_sensitivities: Stores basic sensitivities if the sensitivity relies on combining multiple ones
- null_prob+: State variable
- null_t: State variable
- raw_results: Computed results before applying any transformation algorithm
- sensitivities: Sensitivities produced by each analyzer
(States enabled by default are listed with +)
Initialize CombinedFeaturewiseDatasetMeasure
| Parameters: |
- analyzers (list or None) – List of analyzers to be used. There is no logic to populate
such a list in __call__, so it must be either provided to
the constructor or assigned to .analyzers prior calling
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
- combiner (Functor) – The combiner is only applied if the computed featurewise dataset
measure is more than one-dimensional. This is different from a
transformer, which is always applied. By default, the sum of
absolute values along the second axis is computed.
- transformer (Functor) – This functor is called in __call__() to perform a final
processing step on the to be returned dataset measure. If None,
nothing is called
- null_dist (instance of distribution estimator) – The estimated distribution is used to assign a probability for a
certain value of the computed measure.
|
|---|
-
analyzers
Used analyzers
-
untrain()
Untrain CombinedFDM
-
class mvpa.measures.base.DatasetMeasure(transformer=None, null_dist=None, **kwargs)
Bases: mvpa.misc.state.ClassWithCollections
A measure computed from a Dataset
All dataset measures support arbitrary transformation of the measure
after it has been computed. Transformation are done by processing the
measure with a functor that is specified via the transformer keyword
argument of the constructor. Upon request, the raw measure (before
transformations are applied) is stored in the raw_results state variable.
Additionally all dataset measures support the estimation of the
probabilit(y,ies) of a measure under some distribution. Typically this will
be the NULL distribution (no signal), that can be estimated with
permutation tests. If a distribution estimator instance is passed to the
null_dist keyword argument of the constructor the respective
probabilities are automatically computed and stored in the null_prob
state variable.
Note
For developers: All subclasses shall get all necessary parameters via
their constructor, so it is possible to get the same type of measure for
multiple datasets by passing them to the __call__() method successively.
See also
Please refer to the documentation of the base class for more information:
ClassWithCollections
Note
Available state variables:
- null_prob+: State variable
- null_t: State variable
- raw_results: Computed results before applying any transformation algorithm
(States enabled by default are listed with +)
See also
Please refer to the documentation of the base class for more information:
ClassWithCollections
Does nothing special.
| Parameters: |
- transformer (Functor) – This functor is called in __call__() to perform a final
processing step on the to be returned dataset measure. If None,
nothing is called
- null_dist (instance of distribution estimator) – The estimated distribution is used to assign a probability for a
certain value of the computed measure.
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
|
|---|
-
null_dist
Return Null Distribution estimator
-
null_prob = None
Stores the probability of a measure under the NULL hypothesis
-
null_t = None
Stores the t-score corresponding to null_prob under assumption
of Normal distribution
-
transformer
Return transformer
-
untrain()
‘Untraining’ Measure
Some derived classes might used classifiers, so we need to
untrain those
-
class mvpa.measures.base.FeatureSelectionClassifierSensitivityAnalyzer(*args_, **kwargs_)
Bases: mvpa.measures.base.ProxyClassifierSensitivityAnalyzer
Set sensitivity analyzer output be reverse mapped using mapper of the
slave classifier
Note
Available state variables:
- base_sensitivities: Stores basic sensitivities if the sensitivity relies on combining multiple ones
- clf_sensitivities: Stores sensitivities of the proxied classifier
- null_prob+: State variable
- null_t: State variable
- raw_results: Computed results before applying any transformation algorithm
(States enabled by default are listed with +)
Initialize instance of ProxyClassifierSensitivityAnalyzer
| Parameters: |
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
|
|---|
-
class mvpa.measures.base.FeaturewiseDatasetMeasure(combiner=<function SecondAxisSumOfAbs at 0x4892f50>, **kwargs)
Bases: mvpa.measures.base.DatasetMeasure
A per-feature-measure computed from a Dataset (base class).
Should behave like a DatasetMeasure.
Note
Available state variables:
- base_sensitivities: Stores basic sensitivities if the sensitivity relies on combining multiple ones
- null_prob+: State variable
- null_t: State variable
- raw_results: Computed results before applying any transformation algorithm
(States enabled by default are listed with +)
See also
Please refer to the documentation of the base class for more information:
DatasetMeasure
Initialize
| Parameters: |
- combiner (Functor) – The combiner is only applied if the computed featurewise dataset
measure is more than one-dimensional. This is different from a
transformer, which is always applied. By default, the sum of
absolute values along the second axis is computed.
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
- transformer (Functor) – This functor is called in __call__() to perform a final
processing step on the to be returned dataset measure. If None,
nothing is called
- null_dist (instance of distribution estimator) – The estimated distribution is used to assign a probability for a
certain value of the computed measure.
|
|---|
-
combiner
Return combiner
-
class mvpa.measures.base.MappedClassifierSensitivityAnalyzer(*args_, **kwargs_)
Bases: mvpa.measures.base.ProxyClassifierSensitivityAnalyzer
Set sensitivity analyzer output be reverse mapped using mapper of the
slave classifier
Note
Available state variables:
- base_sensitivities: Stores basic sensitivities if the sensitivity relies on combining multiple ones
- clf_sensitivities: Stores sensitivities of the proxied classifier
- null_prob+: State variable
- null_t: State variable
- raw_results: Computed results before applying any transformation algorithm
(States enabled by default are listed with +)
Initialize instance of ProxyClassifierSensitivityAnalyzer
| Parameters: |
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
|
|---|
-
class mvpa.measures.base.ProxyClassifierSensitivityAnalyzer(*args_, **kwargs_)
Bases: mvpa.measures.base.Sensitivity
Set sensitivity analyzer output just to pass through
Note
Available state variables:
- base_sensitivities: Stores basic sensitivities if the sensitivity relies on combining multiple ones
- clf_sensitivities: Stores sensitivities of the proxied classifier
- null_prob+: State variable
- null_t: State variable
- raw_results: Computed results before applying any transformation algorithm
(States enabled by default are listed with +)
See also
Please refer to the documentation of the base class for more information:
Sensitivity
Initialize instance of ProxyClassifierSensitivityAnalyzer
| Parameters: |
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
|
|---|
-
analyzer
-
untrain()
-
class mvpa.measures.base.Sensitivity(clf, force_training=True, **kwargs)
Bases: mvpa.measures.base.FeaturewiseDatasetMeasure
No documentation found. Sorry!
Note
Available state variables:
- base_sensitivities: Stores basic sensitivities if the sensitivity relies on combining multiple ones
- null_prob+: State variable
- null_t: State variable
- raw_results: Computed results before applying any transformation algorithm
(States enabled by default are listed with +)
Initialize the analyzer with the classifier it shall use.
| Parameters: |
- clf (Classifier) – classifier to use.
- force_training (Bool) – if classifier was already trained – do not retrain
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
- combiner (Functor) – The combiner is only applied if the computed featurewise dataset
measure is more than one-dimensional. This is different from a
transformer, which is always applied. By default, the sum of
absolute values along the second axis is computed.
- transformer (Functor) – This functor is called in __call__() to perform a final
processing step on the to be returned dataset measure. If None,
nothing is called
- null_dist (instance of distribution estimator) – The estimated distribution is used to assign a probability for a
certain value of the computed measure.
|
|---|
-
clf
-
feature_ids
Return feature_ids used by the underlying classifier
-
untrain()
Untrain corresponding classifier for Sensitivity
-
class mvpa.measures.base.SplitFeaturewiseDatasetMeasure(splitter, analyzer, insplit_index=0, combiner=None, **kwargs)
Bases: mvpa.measures.base.FeaturewiseDatasetMeasure
Compute measures across splits for a specific analyzer
Note
Available state variables:
- base_sensitivities: Stores basic sensitivities if the sensitivity relies on combining multiple ones
- null_prob+: State variable
- null_t: State variable
- raw_results: Computed results before applying any transformation algorithm
- sensitivities: Sensitivities produced for each split
- splits: Store the actual splits of the data. Can be memory expensive
(States enabled by default are listed with +)
Initialize SplitFeaturewiseDatasetMeasure
| Parameters: |
- splitter (Splitter) – Splitter to use to split the dataset
- analyzer (DatasetMeasure) – Measure to be used. Could be analyzer as well (XXX)
- insplit_index (int) – splitter generates tuples of dataset on each iteration
(usually 0th for training, 1st for testing).
On what split index in that tuple to operate.
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
- combiner (Functor) – The combiner is only applied if the computed featurewise dataset
measure is more than one-dimensional. This is different from a
transformer, which is always applied. By default, the sum of
absolute values along the second axis is computed.
- transformer (Functor) – This functor is called in __call__() to perform a final
processing step on the to be returned dataset measure. If None,
nothing is called
- null_dist (instance of distribution estimator) – The estimated distribution is used to assign a probability for a
certain value of the computed measure.
|
|---|
-
untrain()
Untrain SplitFeaturewiseDatasetMeasure
-
class mvpa.measures.base.StaticDatasetMeasure(measure=None, bias=None, *args, **kwargs)
Bases: mvpa.measures.base.DatasetMeasure
A static (assigned) sensitivity measure.
Since implementation is generic it might be per feature or
per whole dataset
Note
Available state variables:
- null_prob+: State variable
- null_t: State variable
- raw_results: Computed results before applying any transformation algorithm
(States enabled by default are listed with +)
See also
Please refer to the documentation of the base class for more information:
DatasetMeasure
Initialize.
| Parameters: |
- measure – actual sensitivity to be returned
- bias – optionally available bias
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
- transformer (Functor) – This functor is called in __call__() to perform a final
processing step on the to be returned dataset measure. If None,
nothing is called
- null_dist (instance of distribution estimator) – The estimated distribution is used to assign a probability for a
certain value of the computed measure.
|
|---|
-
bias