This content refers to the previous stable release of PyMVPA.
Please visit
www.pymvpa.org for the most
recent version of PyMVPA and its documentation.
clfs.stats
Module: clfs.stats
Inheritance diagram for mvpa.clfs.stats:
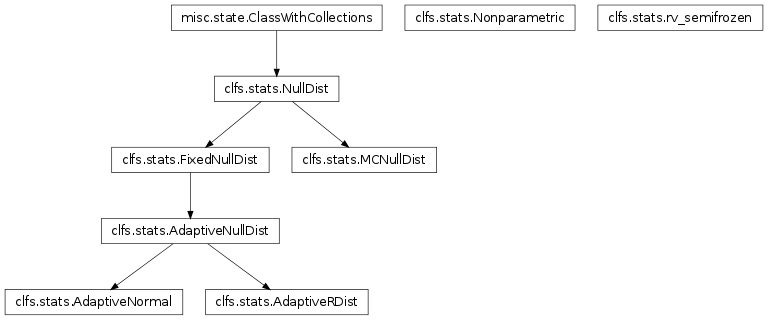
Estimator for classifier error distributions.
Classes
-
class mvpa.clfs.stats.AdaptiveNormal(dist, **kwargs)
Bases: mvpa.clfs.stats.AdaptiveNullDist
Adaptive Normal Distribution: params are (0, sqrt(1/nfeatures))
Note
Available state variables:
(States enabled by default are listed with +)
See also
Please refer to the documentation of the base class for more information:
AdaptiveNullDist
| Parameters: |
- dist (distribution object) – This can be any object the has a cdf() method to report the
cumulative distribition function values.
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
- tail (str (‘left’, ‘right’, ‘any’, ‘both’)) – Which tail of the distribution to report. For ‘any’ and ‘both’
it chooses the tail it belongs to based on the comparison to
p=0.5. In the case of ‘any’ significance is taken like in a
one-tailed test.
|
|---|
-
class mvpa.clfs.stats.AdaptiveNullDist(dist, **kwargs)
Bases: mvpa.clfs.stats.FixedNullDist
Adaptive distribution which adjusts parameters according to the data
WiP: internal implementation might change
Note
Available state variables:
(States enabled by default are listed with +)
See also
Please refer to the documentation of the base class for more information:
FixedNullDist
| Parameters: |
- dist (distribution object) – This can be any object the has a cdf() method to report the
cumulative distribition function values.
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
- tail (str (‘left’, ‘right’, ‘any’, ‘both’)) – Which tail of the distribution to report. For ‘any’ and ‘both’
it chooses the tail it belongs to based on the comparison to
p=0.5. In the case of ‘any’ significance is taken like in a
one-tailed test.
|
|---|
-
fit(measure, wdata, vdata=None)
Cares about dimensionality of the feature space in measure
-
class mvpa.clfs.stats.AdaptiveRDist(dist, **kwargs)
Bases: mvpa.clfs.stats.AdaptiveNullDist
Adaptive rdist: params are (nfeatures-1, 0, 1)
Note
Available state variables:
(States enabled by default are listed with +)
See also
Please refer to the documentation of the base class for more information:
AdaptiveNullDist
| Parameters: |
- dist (distribution object) – This can be any object the has a cdf() method to report the
cumulative distribition function values.
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
- tail (str (‘left’, ‘right’, ‘any’, ‘both’)) – Which tail of the distribution to report. For ‘any’ and ‘both’
it chooses the tail it belongs to based on the comparison to
p=0.5. In the case of ‘any’ significance is taken like in a
one-tailed test.
|
|---|
-
cdf(x)
-
class mvpa.clfs.stats.FixedNullDist(dist, **kwargs)
Bases: mvpa.clfs.stats.NullDist
Proxy/Adaptor class for SciPy distributions.
All distributions from SciPy’s ‘stats’ module can be used with this class.
>>> import numpy as N
>>> from scipy import stats
>>> from mvpa.clfs.stats import FixedNullDist
>>>
>>> dist = FixedNullDist(stats.norm(loc=2, scale=4))
>>> dist.p(2)
0.5
>>>
>>> dist.cdf(N.arange(5))
array([ 0.30853754, 0.40129367, 0.5 , 0.59870633, 0.69146246])
>>>
>>> dist = FixedNullDist(stats.norm(loc=2, scale=4), tail='right')
>>> dist.p(N.arange(5))
array([ 0.69146246, 0.59870633, 0.5 , 0.40129367, 0.30853754])
Note
Available state variables:
(States enabled by default are listed with +)
See also
Please refer to the documentation of the base class for more information:
NullDist
| Parameters: |
- dist (distribution object) – This can be any object the has a cdf() method to report the
cumulative distribition function values.
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
- tail (str (‘left’, ‘right’, ‘any’, ‘both’)) – Which tail of the distribution to report. For ‘any’ and ‘both’
it chooses the tail it belongs to based on the comparison to
p=0.5. In the case of ‘any’ significance is taken like in a
one-tailed test.
|
|---|
-
cdf(x)
Return value of the cumulative distribution function at x.
-
fit(measure, wdata, vdata=None)
Does nothing since the distribution is already fixed.
-
class mvpa.clfs.stats.MCNullDist(dist_class=<class 'mvpa.clfs.stats.Nonparametric'>, permutations=100, **kwargs)
Bases: mvpa.clfs.stats.NullDist
Null-hypothesis distribution is estimated from randomly permuted data labels.
The distribution is estimated by calling fit() with an appropriate
DatasetMeasure or TransferError instance and a training and a
validation dataset (in case of a TransferError). For a customizable
amount of cycles the training data labels are permuted and the
corresponding measure computed. In case of a TransferError this is the
error when predicting the correct labels of the validation dataset.
The distribution can be queried using the cdf() method, which can be
configured to report probabilities/frequencies from left or right tail,
i.e. fraction of the distribution that is lower or larger than some
critical value.
This class also supports FeaturewiseDatasetMeasure. In that case cdf()
returns an array of featurewise probabilities/frequencies.
Note
Available state variables:
- dist_samples: Samples obtained for each permutation
(States enabled by default are listed with +)
See also
Please refer to the documentation of the base class for more information:
NullDist
Initialize Monte-Carlo Permutation Null-hypothesis testing
| Parameters: |
- dist_class (class) – This can be any class which provides parameters estimate
using fit() method to initialize the instance, and
provides cdf(x) method for estimating value of x in CDF.
All distributions from SciPy’s ‘stats’ module can be used.
- permutations (int) – This many permutations of label will be performed to
determine the distribution under the null hypothesis.
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
- tail (str (‘left’, ‘right’, ‘any’, ‘both’)) – Which tail of the distribution to report. For ‘any’ and ‘both’
it chooses the tail it belongs to based on the comparison to
p=0.5. In the case of ‘any’ significance is taken like in a
one-tailed test.
|
|---|
-
cdf(x)
Return value of the cumulative distribution function at x.
-
clean()
Clean stored distributions
Storing all of the distributions might be too expensive
(e.g. in case of Nonparametric), and the scope of the object
might be too broad to wait for it to be destroyed. Clean would
bind dist_samples to empty list to let gc revoke the memory.
-
fit(measure, wdata, vdata=None)
Fit the distribution by performing multiple cycles which repeatedly
permuted labels in the training dataset.
| Parameters: |
- measure ((Featurewise)`DatasetMeasure` | TransferError) – TransferError instance used to compute all errors.
- wdata (Dataset which gets permuted and used to compute the) – measure/transfer error multiple times.
- vdata (Dataset used for validation.) – If provided measure is assumed to be a TransferError and
working and validation dataset are passed onto it.
|
|---|
-
class mvpa.clfs.stats.Nonparametric(dist_samples, correction='clip')
Bases: object
Non-parametric 1d distribution – derives cdf based on stored values.
Introduced to complement parametric distributions present in scipy.stats.
| Parameters: |
- dist_samples (ndarray) – Samples to be used to assess the distribution.
- correction ({‘clip’} or None, optional) – Determines the behavior when .cdf is queried. If None – no
correction is made. If ‘clip’ – values are clipped to lie
in the range [1/(N+2), (N+1)/(N+2)] (simply because
non-parametric assessment lacks the power to resolve with
higher precision in the tails, so ‘imagery’ samples are
placed in each of the two tails).
|
|---|
-
cdf(x)
Returns the cdf value at x.
-
static fit(dist_samples)
-
class mvpa.clfs.stats.NullDist(tail='both', **kwargs)
Bases: mvpa.misc.state.ClassWithCollections
Base class for null-hypothesis testing.
Note
Available state variables:
(States enabled by default are listed with +)
See also
Please refer to the documentation of the base class for more information:
ClassWithCollections
Cheap initialization.
| Parameters: |
- tail (str (‘left’, ‘right’, ‘any’, ‘both’)) – Which tail of the distribution to report. For ‘any’ and ‘both’
it chooses the tail it belongs to based on the comparison to
p=0.5. In the case of ‘any’ significance is taken like in a
one-tailed test.
- enable_states (None or list of basestring) – Names of the state variables which should be enabled additionally
to default ones
- disable_states (None or list of basestring) – Names of the state variables which should be disabled
|
|---|
-
cdf(x)
Implementations return the value of the cumulative distribution
function (left or right tail dpending on the setting).
-
fit(measure, wdata, vdata=None)
Implement to fit the distribution to the data.
-
p(x, **kwargs)
Returns the p-value for values of x.
Returned values are determined left, right, or from any tail
depending on the constructor setting.
In case a FeaturewiseDatasetMeasure was used to estimate the
distribution the method returns an array. In that case x can be
a scalar value or an array of a matching shape.
-
tail
Functions
-
mvpa.clfs.stats.autoNullDist(dist)
Cheater for human beings – wraps dist if needed with some
NullDist
tail and other arguments are assumed to be default as in
NullDist/MCNullDist
-
mvpa.clfs.stats.nanmean(x, axis=0)
Compute the mean over the given axis ignoring nans.
| Parameters: |
- x (ndarray) – input array
- axis (int) – axis along which the mean is computed.
|
|---|
| Results : |
- m : float
the mean.
|
|---|